Lab 11 - Kubernetes Horizontal Pod Autoscaler
Overview¶
In this lab session we will check how to enable HPA and configure it for our Use Case deployment. This week's tasks are:
- Setup HPA
- Install Prometheus adapter
- Try out a simple HPA use case
- Configure HPA for the use case microservices
Horizontal Pod Automatic Scaler¶
Horizontal Pod Automatic Scaler (HPA) was covered in Lecture 11. HPA is a Kubernetes controller that can be configured to track the performance of Workflows like Deployments and StatefulSets (by defining a HPA resource for them) and scales the number of their replicas based on chosen performance metric targets and scaling behaviour policies.
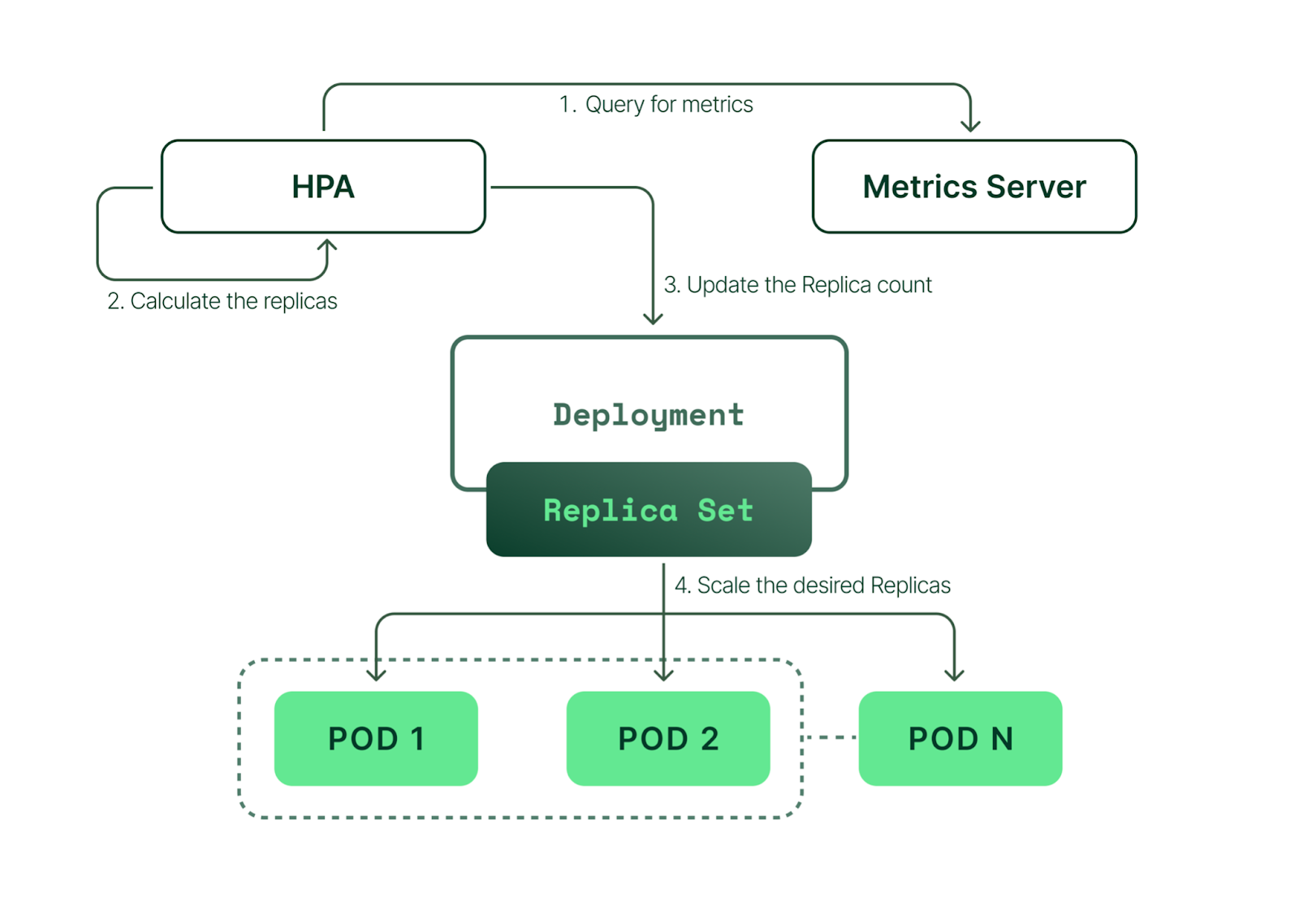 (Source: link )
(Source: link )
HPA requires that Pod metrics are made available through metrics.k8s.io, custom.metrics.k8s.io, or external.metrics.k8s.io API. Usually this requires deploying a Metrics server, but we will use the Prometheus based monitoring to achieve this.
Learn more about HPA: https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
Configuring Monitoring¶
HPA needs access to Pod metrics to be able to decide when to scale the number of Pod replicas. Kubernetes Metrics server aggregates resource usage values exposed by the Kubelet and exposes them in the metrics.k8s.io API to be used for scaling.
Instead of installing Metrics Server, we will use our Prometheus monitoring setup. For his we will need to install a Prometheus adapter which is able to expose custom metrics and provide the same API as the Kubernetes Metrics Server would. We will use the prometheus-community/prometheus-adapter Helm Chart.
The repository for the Prometheus community stack is located here: https://github.com/prometheus-operator/kube-prometheus
You can also take a look at the Helm repository: https://prometheus-community.github.io/helm-charts
Complete
Setup the Helm repository as shown on the Helm repository site, using the helm repo add command.
Export the default Helm values of the Prometheus adapter: helm show values prometheus-community/prometheus-adapter > adapter-all-values.yaml
Adjust the values inside the Yaml file. Change the prometheus.url value to correct service address in the monitoring namespace. You may also need to change the service port.
Also, uncomment all the lines (near the middle of the file) in the resource: block. This will expose cpu and memory metrics for the HPA through the normal Kubernetes Metrics API metrics.k8s.io.
Install the prometheus-community/prometheus-adapter Helm chart. Set the version to 4.11.0, use monitoring namespace and use the prepared values file.
Verify
The prometheus-adapter pod will be deployed inside the monitoring namespace.
Verify that the mertics server Pod starts up properly.
You can then check that node and pod metrics are available through the API using the following command: kubectl get --raw /apis/metrics.k8s.io/v1beta1 | jq "."
Trying out HPA example¶
Now that we have a running metrics server, we will try out a simple scenario of automatically scaling a Kubernetes deployment using HPA.
We are mainly following the Kubernetes documentation example for this task: https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/
Complete
Create a new namespace hpa-test.
Deploy the following manifest in the hpa-test namespace:
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
spec:
selector:
matchLabels:
run: php-apache
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
image: registry.k8s.io/hpa-example
ports:
- containerPort: 80
resources:
limits:
cpu: 200m
requests:
cpu: 100m
---
apiVersion: v1
kind: Service
metadata:
name: php-apache
labels:
run: php-apache
spec:
ports:
- port: 80
selector:
run: php-apache
This will deploy a simple PHP web app in a Apache web server container. One thing to note is that it has no ReplicaSet configured.
Verify
Check that the pods are running. Also check that the web server responds properly:
curl http://php-apache.hpa-test.svc
PS! This service url is only available from inside other containers. Use a direct service IP, port forwarder or some other container to access it. For example, using a temporary container:
kubectl run -i --tty --rm debug -n hpa-test --image=registry.hpc.ut.ee/mirror/curlimages/curl --restart=Never -- curl http://php-apache.hpa-test.svc
NB! You should be careful about trusting containers from global registries
Complete
Next, we will create a HPA configuration for enabling automatic scaling of this deployment.
Create the folowing manifest for the HPA and apply it.
This will configure the HPA controller to track the performance of the php-apache deployment.
We configure the target metric to be CPU utilization and configure the automatic scaling target to be average 50% CPU utilization.
The HPA controller will try to keep the average CPU utilization below 50%, while adding Pod replicas when it increases above this target and removing replicas when the average CPU utilization drops below it.
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
namespace: hpa-test
spec:
minReplicas: 1
maxReplicas: 10
metrics:
- resource:
name: cpu
target:
averageUtilization: 50
type: Utilization
type: Resource
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
Verify
Lets first check if HPA configuration is working and whether it is able to get access to the CPU metrics of a pod. Check the status of the created HPA with the following command:
kubectl get hpa php-apache -n hpa-test
After a new HPA has been created, it will take some time before metrics are first fetched from Prometheus. Once the metrics are available, you should see a similar output to the following, where the TARGETS column show the current and target CPU percentage.
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE php-apache Deployment/php-apache cpu: 1%/50% 1 10 1 61s
Verify
Lets now verify that the HPA scaling works as required by generating synthetic traffic for the deployed application to initiate scaling operations.
Lets sart watching the current state of the HPA configuration. Run the following command to keep checking the state changes of the created HPA:
kubectl get hpa php-apache -n hpa-test --watch
Open a different terminal and start generating traffic:
kubectl run -i --tty load-generator --rm --image=busybox:1.28 --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache.hpa-test.svc; done"
The first terminal window should start showing a changed state where the CPU usage raises above 50% and you should notice that HPA starts scaling the number of replicas after a while.
Danger
Do not leave the synthetic traffic generator running for long periods. Verify that the number of replicas are scaled back to 1 after you stop the traffic generation (This can take a few minutes).
Configuring HPA for the History Server microservice¶
The next task is to configure HPA for the Electricity Calculator History Server microservice.
Complete
Double check that your History Server deployment has resoruce request and limit values set.
Create a new HPA for the History Server deployment we have earlier set up in the production namespace. Set the number of minimum replicas to 1, maximum replicas to 10, and average CPU utilization to 60%.
If you notice that History Server scaling is too agressive, and want to configure the behaviour of scaling, check the Configuring scaling behavior guide in the Kubernetes HPA documentation.
One reason for default configuration might not work perfectly is that it takes some time before History Server is verified to be in ready state (we configured readyness probes).
You can change the default values of the HPA Policy, including how long the scaling trigger event (CPU higher than 60% in our case) must last before the HPA controller takes action, what is the duration that is used for computing the average, how many Pods can be added or removed at once, how often scaling descisions can be initiated, and several other things.
Verify
Generate some traffic to the History Server deployment and verify that the number of Pods is scaled up and down as you create and stop generated traffic.
Configuring HPA for the Application Server microservice¶
The next task is to configure HPA also for the Application Server microservice. But this time we will use the custom application_server_requests_total metric that we implemented in an lab 9.
Complete
Configure a new Custom metric in the Prometheus Adapter Helm values file under the rules.custom YAML block. It should look something like this:
custom:
- seriesQuery: '{__name__=~"^application_server_requests_total$"}'
resources:
overrides:
kubernetes_namespace:
resource: namespace
kubernetes_pod_name:
resource: pod
name:
matches: ""
as: "application_server_requests_per_second"
metricsQuery: avg(rate(<<.Series>>{<<.LabelMatchers>>}[2m])) by (<<.GroupBy>>)
The seriesQuery field defines which metric is processed. We have configured to look for a metric with application_server_requests_total name.
The resources field maps which metric labels match Kubernetes namespace and pod names. You may have to change these values if the metric labels are different in your case, as they depend on how you made prometheus scrape your use case metrics. Also, you will have to make sure that your metrics contain both namespace and pod labels. Best way to do it is to make prometheus assign them when collecting/scaping metrics from the application server pods.
You could achieve that by adding the following labels to the Prometheus application server scraping configuration:
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
The name.as field defines the name for the new custom metric. And metricsQuery defines what Prometheus query we use to calculate its value. It applies average and rate functions on them to compute average requests per second in a 2 minute window.
As a result, a new custom metric named application_server_requests_per_second will be created and it should be available through the Prometheus adapter custom.metrics.k8s.io API.
It is also suggested to disable other custom metrics so it would be easier to debug. Set the rules.default value to false:
rules:
default: false
Verify
Check that the application_server_requests_per_second metric shows up in the list of custom metrics:
kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1 | jq .
Result should look something like this if other metrics were disabled. Otherwise the output would be much longer.
{
"kind": "APIResourceList",
"apiVersion": "v1",
"groupVersion": "custom.metrics.k8s.io/v1beta1",
"resources": [
{
"name": "namespaces/application_server_requests_per_second",
"singularName": "",
"namespaced": false,
"kind": "MetricValueList",
"verbs": [
"get"
]
},
{
"name": "pods/application_server_requests_per_second",
"singularName": "",
"namespaced": true,
"kind": "MetricValueList",
"verbs": [
"get"
]
}
]
}
Debug
If the metric does not show up, then there is something wrong either in the Prometheus scraping configuration or in the prometheus adapter custom metric specification. Check that:
- Prometheus
application_server_requests_totalmetric is successfully collected from your Application server and shows up in prometheus. - Check that
application_server_requests_totalhas namespace and pod labels. - Check that the Prometheus adapter pod is running without errors and check its logs.
Here is an example how the basic application_server_requests_total metric should look like in the prometheus server:
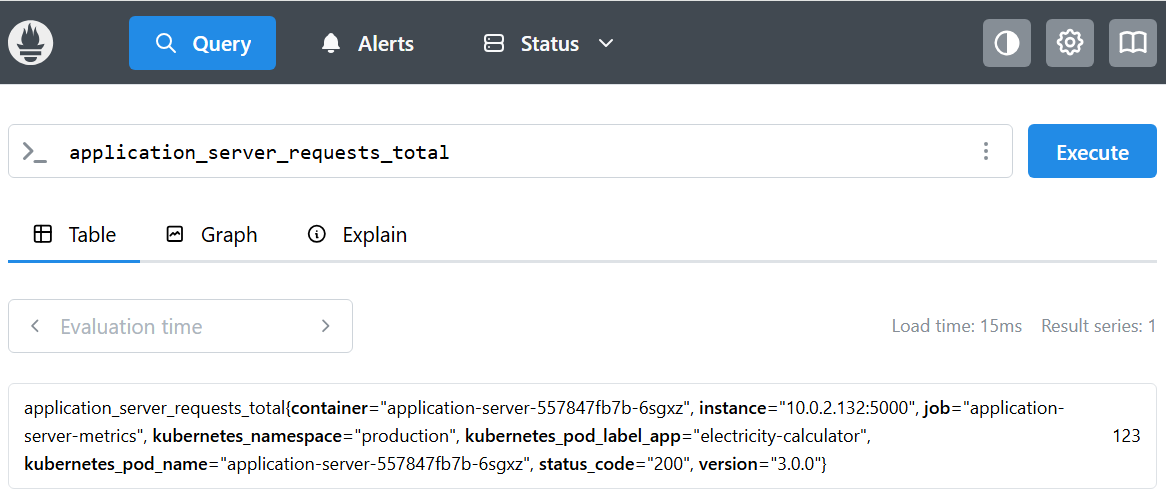
Verify
Check that the new custom application_server_requests_per_second metric value becomes available through the prometheus adapter API:
kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1/namespaces/production/pods/*/application_server_requests_per_second | jq .
You should see one JSON block for every Pod that has application_server_requests_per_second metric available. If there are have been no recent requests the value of the metric would be 0.
Example output:
{
"kind": "MetricValueList",
"apiVersion": "custom.metrics.k8s.io/v1beta1",
"metadata": {},
"items": [
{
"describedObject": {
"kind": "Pod",
"namespace": "production",
"name": "application-server-6f8687f79c-p6pxp",
"apiVersion": "/v1"
},
"metricName": "application_server_requests_per_second",
"timestamp": "2025-12-04T08:01:30Z",
"value": "2827m",
"selector": null
}
]
}
The small m at the end of the metric value represents milli value or one thousanths of a metric. In this case, 2827m or 2827 milli requests per second means 2.827 requests per second.
Send successful requests against your Applications server in the correct namespace and verify that the value of the metric inscreases.
Complete
Create a HPA manifest for the Application Server deployment and apply it. Because we are now using Custom metric, set the metric name to application_server_requests_per_second and metric type to be Pods. Use AverageValue type target for metric and assign desired metric value to 10 (10 requests per second).
You will find some information about using Custom Pod metrics in the Kubernetes HPA walkthrough
Verify
Check that the Application server HPA shows the current metric.

Generate continious traffic to the Application Server deployment and verify that the number of Pods is scaled up and down as you create and stop generated traffic. You can use the same load-generator approach as in the previous tasks.
How long does it take for Kubernetes to scale replicas back down once the traffic slows down?
Complete
Cleanup the hpa-test namespace, remove the deployment, service and php-apache HPA configuration.