Lab 13 - Kubernetes security
Overview¶
- Base security methods in Kubernetes
- Pod Security Admission
- Network policies
- Service mesh
- Defending
- Detection with Tetragon
- Enforcement with Kyverno
Base security methods¶
There are two main runtime security methods in Kubernetes that cluster administrators and application developers can use to enforce security rules upon the cluster, or specific namespaces.
- Pod Security Admission rules
- Network policies
There are also other tools and possibilities, like Pod security contexts, which define privilege and access control settings for Pods or containers, but these are more difficult to configure and enforce, as they're application specific. Later on in the lab, you'll see how to do that as well, but if you need to start off with Kubernetes security, these two methods should be first in line, as they cover the most ground.
Pod Security Admission¶
Pod Security Admission is a technology, that enforces a specific rule-set on the pods inside the namespace, where the Pod Security Admission rules have been set up. The Kubernetes Pod Security defines three standards:
- Privileged - Unrestricted policy, providing the widest possible level of permissions. This policy allows for known privilege escalations.
- Baseline - Minimally restrictive policy which prevents known privilege escalations. Allows the default (minimally specified) Pod configuration.
- Restricted - Heavily restricted policy, following current Pod hardening best practices.
All of these standards have their own use cases:
The Baseline policy is aimed at ease of adoption for common containerized workloads while preventing known privilege escalations. This policy is targeted at application operators and developers of non-critical applications.
This standard should work for most applications, and defends against the known privilege escalations. If you don't know which policy the application needs, this one should be a good starting point.
The Privileged policy is purposely-open, and entirely unrestricted. This type of policy is typically aimed at system- and infrastructure-level workloads managed by privileged, trusted users.
Most applications in the cluster do not need access to system level things, like mounting folders from Kubernetes node file system. But some technologies, especially monitoring (node-exporter), storage (longhorn), GPU tools or even networking tools might still need access to them. This is the policy to use in that case. This is the same as not using a policy, but defining it helps to keep the definitions explicit, and will help with other tools you'll see later in the lab.
The Restricted policy is aimed at enforcing current Pod hardening best practices, at the expense of some compatibility. It is targeted at operators and developers of security-critical applications, as well as lower-trust users.
This is the most restrictive policy, that on top of what baseline does, requires the pods to:
- Run as non-root users.
- Use only very specific volume types
- Define a specific
seccompprofile. - Containers must drop the
ALLcapability set, and are only allowed to useNET_BIND_SERVICE.
Adding this policy to a namespace is very straightforward. You need to add these labels to the Namespace manifest, like so:
apiVersion: v1
kind: Namespace
metadata:
labels:
# The per-mode level label indicates which policy level to apply for the mode.
#
# MODE must be one of `enforce`, `audit`, or `warn`.
# LEVEL must be one of `privileged`, `baseline`, or `restricted`.
pod-security.kubernetes.io/<MODE>: <LEVEL>
# Optional: per-mode version label that can be used to pin the policy to the
# version that shipped with a given Kubernetes minor version (for example v1.28).
#
# MODE must be one of `enforce`, `audit`, or `warn`.
# VERSION must be a valid Kubernetes minor version, or `latest`.
pod-security.kubernetes.io/<MODE>-version: <VERSION>
name: <namespace-name>
You need to substitute the mode with either enforce, audit or warn, depending on what you want to do. warn lets the user now, when deploying something that would go against the defined Pod security level, audit logs it for Kubernetes admins, and enforce rejects the submitted workloads during submission.
Try setting up a new namespace, first without a Pod security standard defined.
Complete
Create a new namespace called pod-security-demo. Do not set pod-security rules yet. First, deploy a manifest there:
apiVersion: v1
kind: Pod
metadata:
name: high-risk-pod
namespace: pod-security-demo
spec:
containers:
- name: high-risk-container
image: nginx
volumeMounts:
- name: shadow
mountPath: /mnt/shadow
volumes:
- name: shadow
hostPath:
path: /etc/shadow
After deployment, you can exec into the container, to run commands, and see, that it has, indeed, mounted the shadow file of the system. This is the file that contains the password hashes of the system, if there are any users with passwords. The same method could be used to, for example, mount the /root/.ssh/authorized_keys file, and you can even edit it through the container!
[root@teacher-test lab12]# kubectl exec -ti pod/high-risk-pod -n pod-security-demo /bin/bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
root@high-risk-pod:/# cat /mnt/shadow
...
This also works with any non-privileged Kubernetes account. If you have permissions to create Pods, Deployments, Jobs, CronJobs, StatefulSets, ReplicaSets or DaemonSets, you can use this method to try to get access to Kubernetes hosts by default. Also, if a container has been mounted a token, which is allowed to deploy Pods in some way, then those also can do the same. You can test this out by creating a new user and using that to try it out.
Now that you established, that by default, Kubernetes doesn't really protect you from malicious workloads, try out the first layer of defense - Pod security admission.
Complete
Edit the Namespace manifest to include the following lines:
metadata:
labels:
pod-security.kubernetes.io/enforce: baseline
pod-security.kubernetes.io/enforce-version: latest
And deploy the namespace. Something you'll see, is that you'll be warned about Pods that violate the rules, but nothing happens to those Pods automatically..
Warning: existing pods in namespace "pod-security-demo" violate the new PodSecurity enforce level "baseline:latest"
Warning: high-risk-pod: hostPath volumes
You can still go and use the existing container for maliciousness. To finally fix this issue, you need to first delete the deployment, and then try to deploy it again.
Verify
When deploying it again, you should be denied with:
Error from server (Forbidden): error when creating "podsecurity.yaml": pods "high-risk-pod" is forbidden: violates PodSecurity "baseline:latest": hostPath volumes (volume "shadow")
Which means, that now the Pod security is working, and disallows running such Pods in this namespace.
As said before, due to how easy this method is to setup, and how much it protects, you should always start securing your cluster from setting up namespaces properly with Pod security rules. As you saw, this needs to be done the moment a namespace is made to be fully effective. Always make sure to choose the correct security level though, things like kube-system, longhorn or even node-exporter need access to host system, which means you'd have to use privileged level.
Network policies¶
You've used some NetworkPolicy objects in previous labs, but so far it has been fairly random and one-off. Network policies in Kubernetes can be thought of to work like a firewall in other systems. If done properly, a system of NetworkPolicy rules can help largely with preventing initial intrusion, as you can define what should be able to access where.
As malicious example you can try connecting from an existing Kubernetes Pod in any namespace to your Longhorn namespace's longhorn-ui Pod.
[root@teacher-test lab12]# kubectl exec -ti pod/high-risk-pod -n pod-security-demo /bin/bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
root@high-risk-pod:/# curl 10.0.0.58:8000
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<!--[if lte IE 10]>
<script
src="https://as.alipayobjects.com/g/component/??console-polyfill/0.2.2/index.js,media-match/2.0.2/media.match.min.js"></script>
<![endif]-->
<style>
::-webkit-scrollbar {
width: 10px;
height: 1px;
}
::-webkit-scrollbar-thumb {
border-radius: 10px;
-webkit-box-shadow: inset 0 0 5px rgba(0,0,0,0.1);
background: #535353;
}
</style>
<link href="./styles.css?c378196633c22a6f7698" rel="stylesheet"></head>
<body>
<div id="root"></div>
<script type="text/javascript" src="./runtime~main.6d7bda24.js?c378196633c22a6f7698"></script><script type="text/javascript" src="./styles.f40bcd81.async.js?c378196633c22a6f7698"></script><script type="text/javascript" src="./main.4a045fc1.async.js?c378196633c22a6f7698"></script></body>
</html>
As you can see, it's up to the maintainer of the application to defend their application and namespace. Longhorn, by default, does none of this - there's no authentication or network policies - so anyone in the cluster can access the Longhorn UI, which allows to configure the whole storage layer, including save backups to some remote location or delete the volumes.
A solution to this is to have properly setup network policies in all namespaces. There's two steps to this - first is to have network policies for all of your cluster infrastructure namespaces like kube-system, longhorn, prometheus and any other important ones. The second step is to force all other namespaces to also have network policies.
Pod capabilities¶
Pod Capabilities in Kubernetes refer to specific privileges that can be granted to a pod, allowing it to perform operations that are normally restricted. Derived from Linux capabilities, these are used to provide fine-grained access control to system-level operations, enhancing security by limiting the privileges of pods.
In Kubernetes, you can assign or remove specific capabilities to a container within a pod, allowing you to adhere to the principle of least privilege. For instance, a common practice is to drop the NET_RAW capability, which reduces the risk of attacks using raw socket communication, like certain types of network spoofing. Another example is adding the SYS_TIME capability to a pod that requires permissions to modify the system clock, which is otherwise restricted.
Pod Security rules define a set of allowed capabilities, allowing to adhere to the principle of least privileges.
sysctl¶
Sysctls in Kubernetes are a mechanism for adjusting kernel parameters at runtime, important for tuning system behavior to enhance security and performance. They are divided into 'safe' and 'unsafe' categories, where safe sysctls are allowed by default, and unsafe sysctls require explicit enabling due to their potential impact on the overall system stability.
In the context of security, sysctls can be used to fine-tune network settings and manage resource limits, thereby mitigating certain types of attacks and resource exhaustion issues. For example, net.ipv4.tcp_syncookies sysctl is used to enable SYN cookies, helping protect against SYN flood attacks. Another example is kernel.shmmax, which can be adjusted to control the maximum size of shared memory segments, preventing excessive resource usage by a single pod. Kubernetes allows these settings to be configured at the pod level, offering a flexible way to apply security enhancements tailored to specific application needs.
Pod Security rules define a set of allowed sysctl parameters, particularly the unsafe ones, thereby mitigating risks associated with altering kernel behavior.
Service mesh¶
Your Kubernetes is using Cilium as a CNI. Beyond offering networking, Cilium is able to provide service mesh functionality. In this lab we shall investigate how to add transparent encryption to communication channel among pods and how to provide extra visibility into used protocols on OSI L7.
Info
Open Systems Interconnection (OSI) model is a well spread conceptual model of networking. Levels are:
- Physical layer
- Data link layer
- Network layer
- Transport layer
- Session layer
- Presentation layer
- Application layer
Examples of L7 include protocols like HTTP, SSH, SMTP, DNS, SNMP and similar.
Enabling mTLS¶
Let's start by opening Hubble UI and selecting lab8 namespace where we have deployed our use case.
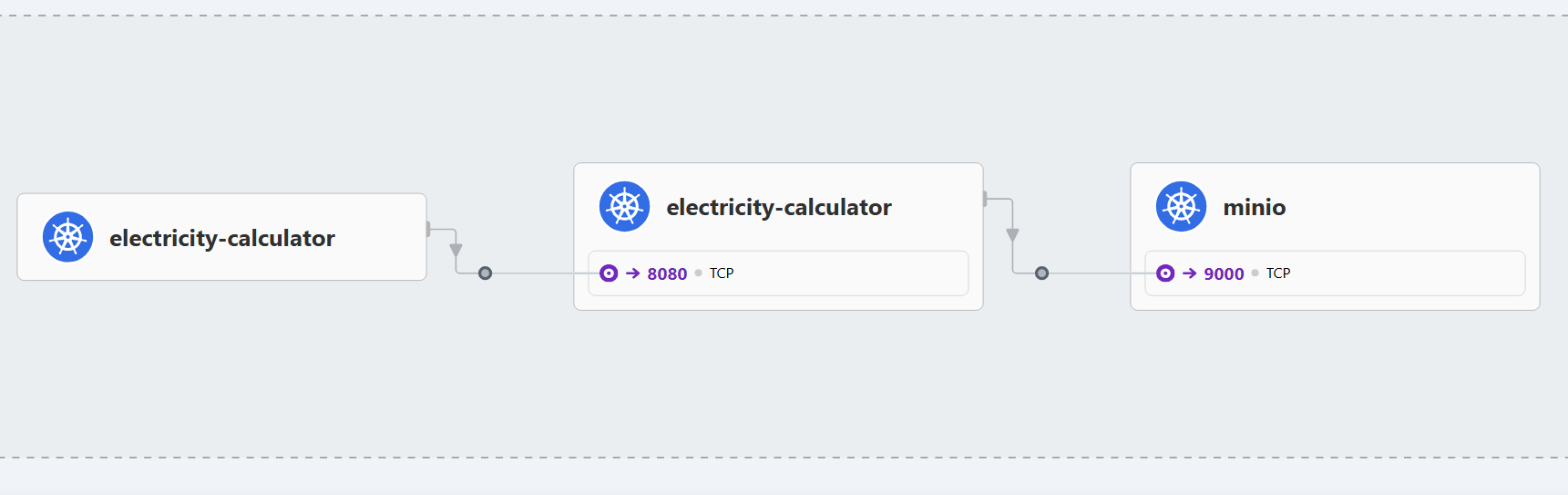
Communication between use case microservice pods and minIO is not authenticated. Let's try and change it to use mutual TLS (mTLS), where both initiator and received authenticate each other. Mutual TLS aims at providing authentication, confidentiality and integrity to service-to-service communications. Cilium relies on SPIFFE and its implementation SPIRE for establishing and attesting identity of services.
Complete
Enable SPIRE server in Cilium deployment. If you are accessing Hubble over NodePort, make sure it is set as well in helm. We will also downgrade cilium version to 1.17.10 as there are issues with mTLS in the later Cilium versions.
/usr/local/bin/cilium upgrade --version 1.17.10 --set authentication.mutual.spire.enabled=true --set authentication.mutual.spire.install.enabled=true --set hubble.ui.service.type=NodePort
If the Cillium CLI has not been installed and the previous command does not work, then you can install it as follows:
CILIUM_CLI_VERSION=$(curl -s https://raw.githubusercontent.com/cilium/cilium-cli/main/stable.txt)
CLI_ARCH=amd64
if [ "$(uname -m)" = "aarch64" ]; then CLI_ARCH=arm64; fi
curl -L --fail --remote-name-all https://github.com/cilium/cilium-cli/releases/download/${CILIUM_CLI_VERSION}/cilium-linux-${CLI_ARCH}.tar.gz{,.sha256sum}
sha256sum --check cilium-linux-${CLI_ARCH}.tar.gz.sha256sum
sudo tar xzvfC cilium-linux-${CLI_ARCH}.tar.gz /usr/local/bin
rm cilium-linux-${CLI_ARCH}.tar.gz{,.sha256sum}
Validate that it works:
$ /usr/local/bin/cilium status
/¯¯\
/¯¯\__/¯¯\ Cilium: OK
\__/¯¯\__/ Operator: OK
/¯¯\__/¯¯\ Envoy DaemonSet: disabled (using embedded mode)
\__/¯¯\__/ Hubble Relay: OK
\__/ ClusterMesh: disabled
Deployment cilium-operator Desired: 1, Ready: 1/1, Available: 1/1
Deployment hubble-relay Desired: 1, Ready: 1/1, Available: 1/1
DaemonSet cilium Desired: 2, Ready: 2/2, Available: 2/2
Deployment hubble-ui Desired: 1, Ready: 1/1, Available: 1/1
Containers: hubble-ui Running: 1
cilium-operator Running: 1
hubble-relay Running: 1
cilium Running: 2
Cluster Pods: 76/77 managed by Cilium
Helm chart version: 1.14.2
Image versions cilium quay.io/cilium/cilium:v1.14.2@sha256:6263f3a3d5d63b267b538298dbeb5ae87da3efacf09a2c620446c873ba807d35: 2
hubble-ui quay.io/cilium/hubble-ui:v0.12.0@sha256:1c876cfa1d5e35bc91e1025c9314f922041592a88b03313c22c1f97a5d2ba88f: 1
hubble-ui quay.io/cilium/hubble-ui-backend:v0.12.0@sha256:8a79a1aad4fc9c2aa2b3e4379af0af872a89fcec9d99e117188190671c66fc2e: 1
cilium-operator quay.io/cilium/operator-generic:v1.14.2@sha256:52f70250dea22e506959439a7c4ea31b10fe8375db62f5c27ab746e3a2af866d: 1
hubble-relay quay.io/cilium/hubble-relay:v1.14.2@sha256:a89030b31f333e8fb1c10d2473250399a1a537c27d022cd8becc1a65d1bef1d6: 1
Verify
Let's make sure that the base infrastructure is working.
- Make sure that SPIRE components are deployed:
$ kubectl get all -n cilium-spire
NAME READY STATUS RESTARTS AGE
pod/spire-agent-4mrbq 1/1 Running 0 3m33s
pod/spire-agent-9nz9r 1/1 Running 0 3m33s
pod/spire-server-0 2/2 Running 0 3m32s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/spire-server ClusterIP 10.96.251.8 <none> 8081/TCP 3m33s
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/spire-agent 2 2 2 2 2 <none> 3m33s
NAME READY AGE
statefulset.apps/spire-server 1/1 3m33s
- Make sure that server is up and running.
$ kubectl exec -n cilium-spire spire-server-0 -c spire-server -- /opt/spire/bin/spire-server healthcheck
Server is healthy.
- Make sure that use case pods have received a Cilium identity
$ kubectl get cep -l microservice=application-server -n lab8 -o wide
NAME SECURITY IDENTITY INGRESS ENFORCEMENT EGRESS ENFORCEMENT VISIBILITY POLICY ENDPOINT STATE IPV4 IPV6
application-server-5d449c5769-bxkjv 2936 ready 10.0.2.233
application-server-5d449c5769-kmk5q 2936 ready 10.0.0.173
application-server-5d449c5769-m487p 2936 ready 10.0.2.145
Complete
Let's now enable transparent mTLS. For that we shall deploy a new pod into the lab8 environment and add a policy that would require all communication to History Server port (For example: 8080 or some other port you use in your container) to be encrypted.
Use the definition below to launch in a lab8 namespace.
apiVersion: v1
kind: Pod
metadata:
labels:
app: pod-worker
name: pod-worker
spec:
containers:
- name: netshoot
image: nicolaka/netshoot:latest
command: ["sleep", "infinite"]
Next, execute a curl request from that Pod against a History Server pod. Make sure that you lookup the IP of a History Server pod your cluster.
$ kubectl exec -it pod-worker -n lab8 -- curl 10.0.1.110:3333
It should work - but checking Hubble we can see that traffic remains plaintext.
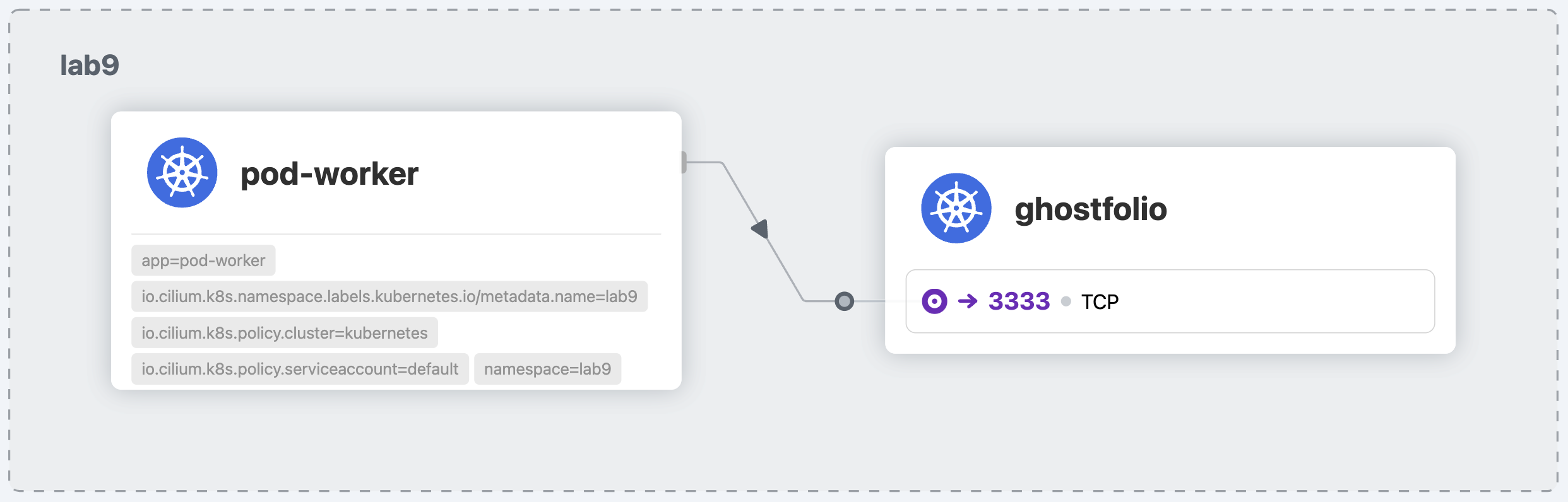
So, next step is to add a policy that will actually force encryption, when communicating with History Server. Cilium policies are very similar to standard Kubernetes network policies, you can also use an online editor to generate a more precise rule.
apiVersion: cilium.io/v2
kind: CiliumNetworkPolicy
metadata:
name: mutual-auth-demo
spec:
endpointSelector:
matchLabels:
app: electricity-calculator
microservice: history-server
ingress:
- fromEndpoints:
- matchLabels:
app: pod-worker
authentication:
mode: "required"
toPorts:
- ports:
- port: "8080"
protocol: TCP
rules:
http:
- method: "GET"
A secret ingredient here is authentication.mode: "required". After applying it for a brief time you might see in the logs dropped packages caused by the requirement for authentication:

Now, try to run curl requests again and check Hubble.
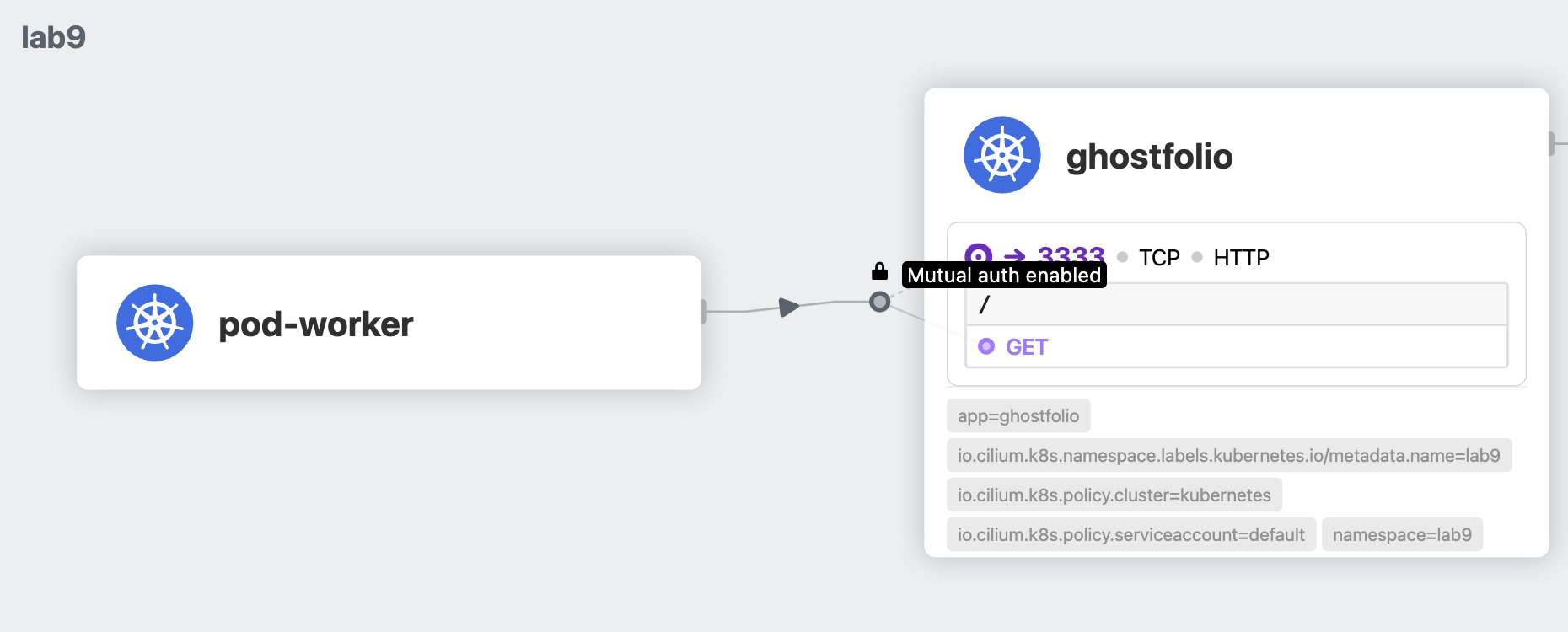
Info
Behind the curtains, Cilium has helped to validate the certificates for the mTLS. Check the logs of the cilium pod on the same Kubernetes node where History Server pod is running.
2023-11-28T18:24:00.387901040-05:00 level=debug msg="Policy is requiring authentication" key="localIdentity=42955, remoteIdentity=51853, remoteNodeID=37176, authType=spire" subsys=auth
2023-11-28T18:24:00.436438988-05:00 level=debug msg="Validating Server SNI" SNI ID=51853 subsys=auth
2023-11-28T18:24:00.436873713-05:00 level=debug msg="Validated certificate" subsys=auth uri-san="[spiffe://spiffe.cilium/identity/51853]"
2023-11-28T18:24:00.439269832-05:00 level=debug msg="Successfully authenticated" key="localIdentity=42955, remoteIdentity=51853, remoteNodeID=37176, authType=spire" remote_node_ip=10.0.0.34 subsys=auth
Note the "remoteIdentity" in the logs. It corresponds to the originator of the traffic, in our case the worker-pod.
$ kubectl get cep -l app=pod-worker -n lab8 -o=jsonpath='{.items[0].status.identity.id}'
51853
Complete
Crate and apply CiliumNetworkPolicy manifests that require authentication between the following use case components in the lab8 namespace:
- Application Server and History Server
- History Server and Minio
- Price Fetcher cron job tasks and History Server
Monitoring¶
Let's try out more fine-grained monitoring of traffic. For that, we need to switch on
Complete
Annote a pod with History Server app with annotation for outgoing traffic. Make sure that pod name and namespace is correct.
$ kubectl annotate pod history-server-646bb975b6-6pcvr -n lab8 policy.cilium.io/proxy-visibility="<Egress/53/UDP/DNS>,<Egress/80/TCP/HTTP>"
Make sure that this annotation remains after the lab as well.
Verify
Execute a workload that triggers external communication, e.g. pulling new package metadata.
$ kubectl exec pod/history-server-646bb975b6-6pcvr -n lab8 -- apk update
NB! The command apk update works for Alpine containers. For Ubuntu containers, it could be apt update instead.
Make sure that you observe detailed information in Hubble:
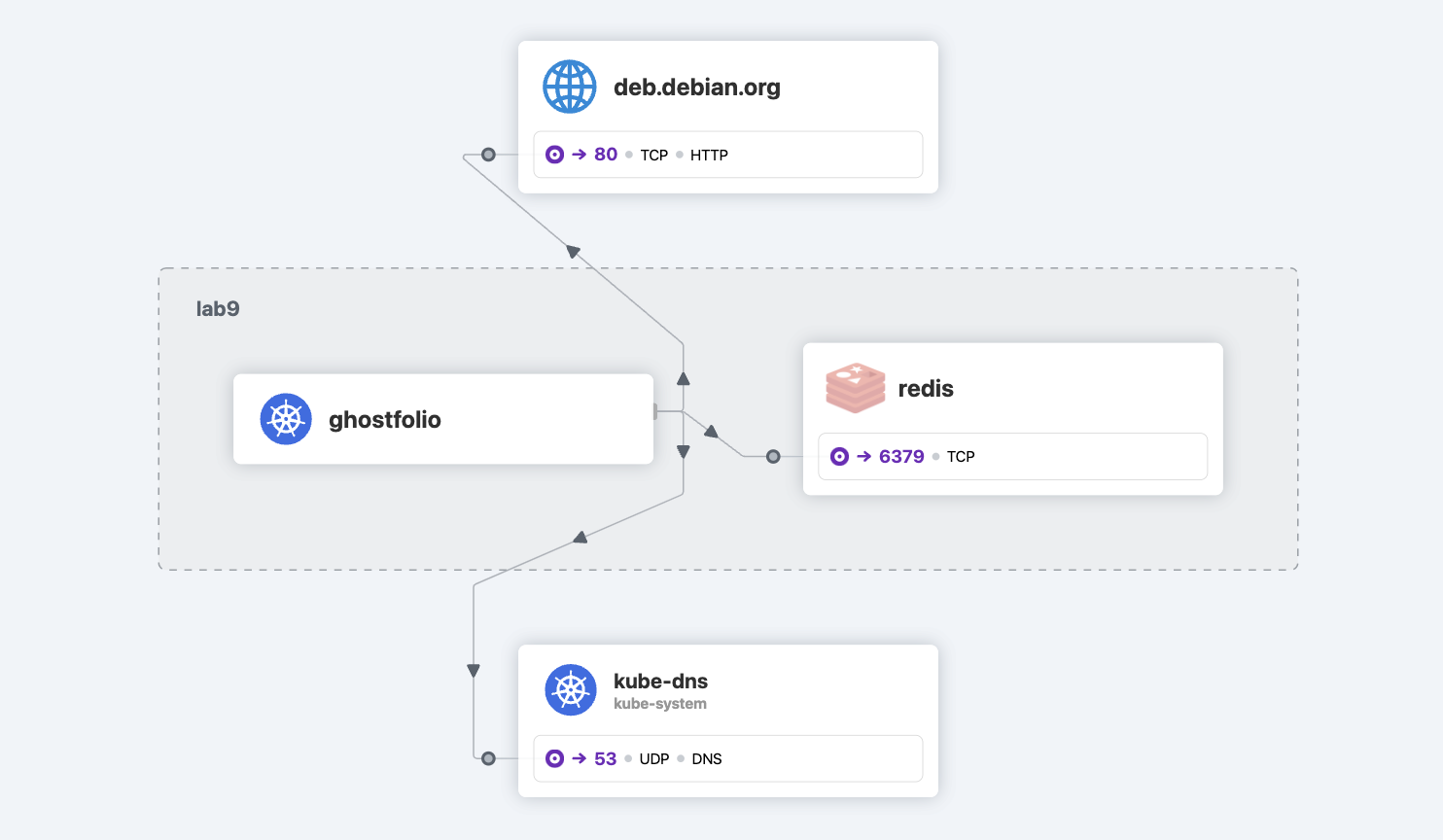

Defending¶
While you've seen a few very powerful defensive technologies shown, these still have quite a few gaps, especially if the Kubernetes cluster isn't made with these defenses in mind. On top of this:
- Any malicious user or service account having access to the network policy rules can edit and remove them.
- It's still impossible to have default rules - making mistakes during application or infrastructure setup is very simple, especially with Helm packaged things, as you can't be sure if it includes the rules or not.
- Already existing resources might behave maliciously.
- You can never be sure if these defenses manage to defend against everything.
Thankfully, all of these issues have solutions. You'll start by fixing the last two first by adding a tool that is capable of detecting all the activities in the cluster, including any commands run in the pods themselves.
The other two issues you'll fix by adding a policy engine, which is capable of enforcing specific rules on the cluster by telling the API server to validate all the submitted manifests against it. It is also even capable of changing those manifests before they are deployed, automatically. This is called mutating and is done with mutatingwebhookcontrollers.
Mutating helps with doing things like, for example, adding nodeAffinity sections to all deployed pods automatically, allowing the cluster to be more balanced and failure tolerant without extra work from application developers or DevOps people.
Detection with Tetragon¶
Making sure your deployed resources don't behave maliciously, or any missed or zero-day issues aren't introduced to the cluster, you need continuous observability into all layers of your Kubernetes cluster.
You already have observability into your container application logs, Kubernetes audit logs, and Kubernetes and host metrics, but you're missing a big part of observability, that gives you information into what's actually running inside your containers, and what are they doing. You can think of this as audit logs for the operating system level, where every execution, file change and connection attempt is logged.
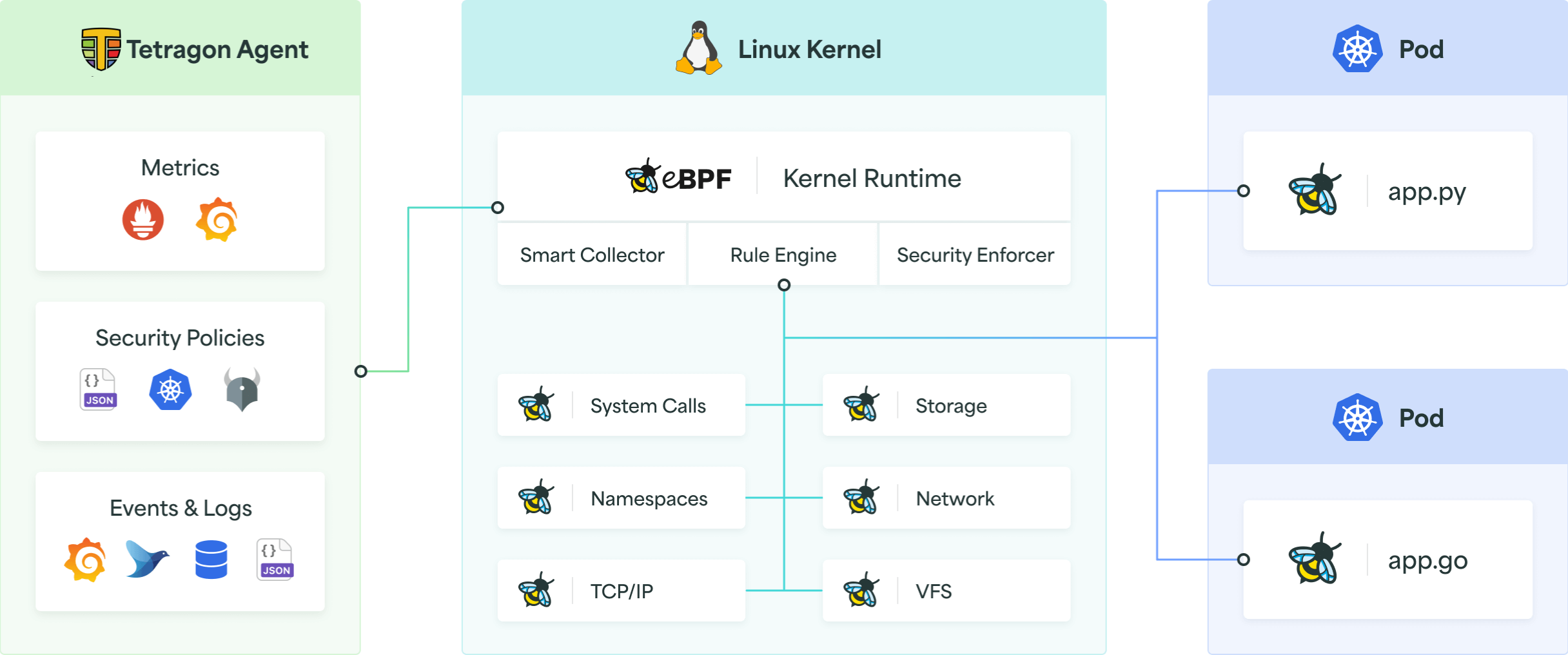
There's quite a few ways to do this, depending on how or what you're running on your machines. auditd is for base Linux, auditbeat for more specific endpoint protocols (like elasticsearch), and finally, in case of Kubernetes, you have Tetragon. Tetragon is very new, made by the same guys who made the Cilium CNI, and uses the same eBPF technology.
Start off by installing Tetragon.
Complete
Install Tetragon to your cluster, with the instructions here. It should be installed to kube-system namespace, as it needs to be very privileged to run:
helm repo add cilium https://helm.cilium.io
helm repo update
helm install tetragon ${EXTRA_HELM_FLAGS} cilium/tetragon -n kube-system
kubectl rollout status -n kube-system ds/tetragon
Tetragon starts up in the kube-system namespace, and instantly starts listening to specific events on all the nodes, in all the pods. By default, it listens to process lifecycle events - process_execute and process_exit, giving overview of all the execution events in your cluster.
You can do way more with Tetragon, like monitoring network traffic, host system, file access, and even more, but that will require extra configuration, and will probably also require more performant machines than ours. Always take into consideration, that monitoring also takes resources, so you should weigh necessity against available resources (budget).
Tetragon starts writing logs about these process lifecycle events to container standard output, but also to the /var/run/cilium/tetragon/ folder on the node. This makes it very easy to ingest the logs into Loki.
Complete
Ingest the JSON logs at /var/run/cilium/tetragon/tetragon.log into Loki with Promtail.
Add this part to config.snippets.extraScrapeConfigs:
- job_name: tetragon
static_configs:
- targets:
- localhost
labels:
job: tetragon
__path__: /var/run/cilium/tetragon/tetragon.log
pipeline_stages:
- json:
expressions:
time:
node_name:
process_exec:
- json:
expressions:
process: process
source: process_exec
- json:
expressions:
process: process
source: process_exit
- json:
expressions:
exec_id: exec_id
pid: pid
uid: uid
binary: binary
arguments: arguments
pod: pod
source: process
- json:
expressions:
pod_namespace: namespace
pod_name: name
container_id: container.id
container_name: container.name
container_image: container.image.name
workload: workload
workload_kind: workload_kind
source: pod
- match:
selector: '{pod_namespace="longhorn-system"}'
action: drop
- labels:
node_name:
arguments:
pod_namespace:
pod_name:
container_name:
container_image:
- timestamp:
source: time
format: RFC3339Nano
This is a very basic configuration, but it'll work for our purposes.
Also, do not forget to add necessary parts to the extraVolumes and extraVolumeMounts part in the Helm chart, otherwise the Promtail pods cannot access the specified folder. Mount the folder, not the log file directly.
Verify
You can verify if everything works by checking if the pods come up, whether the file is a successful target in the Promtail UI, and whether logs start appearing with job: tetragon in Grafana.
The last part to try out is trying to do malicious actions from any pod in the cluster (like the high-risk-pod) we setup in the first part of the lab. You should see the commands run inside the container in the logs, so if that container goes to read /etc/shadow or curl longhorn-ui, you should be able to see this.
Tetragon can be configured also to monitor network events, so all the malicious connections can be logged even better.
In real world, you'd route the events from Tetragon and Kubernetes API into a Security Information and Event Management (SIEM) system, which helps detect, analyze, and respond to security threats. Doing this, and using SIEM, are out of the scope of this course.
Enforcing rules with Kyverno¶
Kyverno is a policy engine, that can validate, mutate, generate, and cleanup Kubernetes resources, and verify image signatures and artifacts to help secure the software supply chain.
Once installed, Kyverno is configured with specific CRD-s. For this lab, you'll be using ClusterPolicy objects.
Danger
When you install Kyverno, it deploys a validating and mutating webhook controllers to the cluster, and all the applied manifests will be checked against those controllers in the future by the Kubernetes API server.
If you're not careful, this might cause a chicken-and-egg problem, where, if the Kyverno controllers are not accessible, you're not able to run any commands against the cluster, because the API server cannot validate the commands, and then denies the commands.
The easiest way to prevent this issue is to not run Kyverno on the kube-system namespace. Then, you might break everything else with your Kyverno policies, but you can at least fix it.
First, start with installing Kyverno.
Complete
Deploy Kyverno to a namespace called kyverno, with the instructions provided here. You can run Kyverno with one replica of every controller to save resources, but in production clusters, you should definitely run multiple replicas.
helm repo add kyverno https://kyverno.github.io/kyverno/
helm repo update
helm install kyverno kyverno/kyverno -n kyverno --create-namespace
Verify
After deployment, make sure all the Kyverno pods are up, and the CRD-s have been made.
Now that Kyverno is up, we can start by defining some policies. Kyverno developers have really thought things through, and published a massive set of public policies which help understand, which policies are useful, how they work, and allow pulling inspiration from.
You'll be defining two policies for different purposes:
- A policy, which mutates the namespace creation manifest to always create namespaces with proper Pod security labels.
- A policy, which makes all namespaces have a
default-denynetwork security policy. This makes sure only whitelisted traffic is allowed.
You should go through the list on the website to see the other very powerful policies possible with Kyverno.
Policy - add Pod Security Admission labels¶
Complete
Apply the first policy, which adds the Pod security labels, if they do not exist yet. You can find this rule in the Kyverno policies page, but you'll also do a few changes to better integrate with your cluster, and not break it.
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: add-psa-labels
annotations:
policies.kyverno.io/title: Add PSA Labels
policies.kyverno.io/category: Pod Security Admission
policies.kyverno.io/severity: medium
kyverno.io/kyverno-version: 1.7.1
policies.kyverno.io/minversion: 1.6.0
kyverno.io/kubernetes-version: "1.24"
policies.kyverno.io/subject: Namespace
policies.kyverno.io/description: >-
Pod Security Admission (PSA) can be controlled via the assignment of labels
at the Namespace level which define the Pod Security Standard (PSS) profile
in use and the action to take. If not using a cluster-wide configuration
via an AdmissionConfiguration file, Namespaces must be explicitly labeled.
This policy assigns the labels `pod-security.kubernetes.io/enforce=baseline`
and `pod-security.kubernetes.io/warn=restricted` to all new Namespaces if
those labels are not included.
spec:
rules:
- name: add-baseline-enforce-restricted-warn
match:
any:
- resources:
kinds:
- Namespace
exclude: # (1)!
resources:
namespaces:
- kube-system
- longhorn-system
- prometheus
- cilium-spire
- loki
mutate: # (2)!
patchStrategicMerge:
metadata:
labels:
+(pod-security.kubernetes.io/enforce): baseline
+(pod-security.kubernetes.io/warn): baseline
- This makes sure that this rule won't be applied to namespaces that definitely should have different rules. While we could also avoid applying this rule by adding correct
privilegedlabels to those namespaces first, we do this as a precaution. - This is where the magic happens. It uses the
patchStartegicMergewith the+operator, which indicates that the label should be added if it's not already present.
Verify
After applying this ClusterPolicy rule to the cluster, try applying the manifest in the Pod Security Admission part of the lab without specifying the Pod security labels yourself. Your workload should still be rejected, and when checking the namespace, it should have the Pod security labels defined with baseline level.
This rule is a mutate rule, which means it is only executed on new submissions to the cluster, which it then potentially changes. While mutateExistingOnPolicyUpdate exists, which allows mutating old resources as well, this configuration requires extra permissions and is asynchronous. It's easier to just add the necessary labels to all old namespaces manually.
Policy - add default blocking NetworkPolicy¶
Complete
Apply the second policy, which creates a NetworkPolicy object to the cluster. This policy allows only intra-namespace traffic between Pods, while any other Pod in any other namespace in the cluster cannot connect. You can find this rule in the Kyverno policies page, but you'll also do a few changes to better integrate with your cluster, and not break it.
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: add-networkpolicy
annotations:
policies.kyverno.io/title: Add Network Policy
policies.kyverno.io/category: Multi-Tenancy, EKS Best Practices
policies.kyverno.io/subject: NetworkPolicy
policies.kyverno.io/minversion: 1.6.0
policies.kyverno.io/description: >-
By default, Kubernetes allows communications across all Pods within a cluster.
The NetworkPolicy resource and a CNI plug-in that supports NetworkPolicy must be used to restrict
communications. A default NetworkPolicy should be configured for each Namespace to
default deny all ingress and egress traffic to the Pods in the Namespace. Application
teams can then configure additional NetworkPolicy resources to allow desired traffic
to application Pods from select sources. This policy will create a new NetworkPolicy resource
named `default-deny` which will deny all traffic anytime a new Namespace is created.
spec:
generateExisting: false # (1)!
rules:
- name: default-deny
match:
any:
- resources:
kinds:
- Namespace
exclude: # (2)!
resources:
namespaces:
- kube-system
- longhorn-system
- kyverno
generate: # (3)!
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
name: default-deny
namespace: "{{request.object.metadata.name}}"
synchronize: true # (4)!
data:
spec:
# select all pods in the namespace
podSelector: {}
ingress:
- from:
- podSelector: {} # (5)!
# deny all traffic
policyTypes:
- Ingress # (6)!
- This flag makes sure the created or updated policy will also be applied to existing resources. We currently leave it as
false, because we want to test it out first, to make sure it won't break anything. - Exclude the system namespaces, as blocking traffic to those can effectively shut your cluster down.
- This is where the magic happens.
generaterules generate new resources to the cluster, when the policy's conditions match. synchronize: truemakes it so, that if the generated resource gets edited or deleted, it gets automatically recreated to the format it's supposed to be. This is what makes enforment with this tool so easy, as namespace bound users cannot delete the generated resources and circumvent the rules.- This part makes all pods in the namespace be accessible by other pods.
- Define only
Ingress(incoming) traffic rule. Skip theEgress(outgoing) one to keep things simple. In high-security environments, you definitely want to define default rules with egress as well.
Verify
After applying the rule to the cluster, make a namespace. Instantly, you should see, that the namespace gets a NetworkPolicy object named default-deny.
If you try to deploy, for example, the nginx Pod inside the cluster, you won't be able to access it from other namespaces. Even kube-system!
This rule is a generate rule, which means it generates new objects to the cluster if the conditions in the policy are matched. By default, it works only when new objects match the conditions, but this behaviour can be changed with the generateExisting option.
Danger
Something to be very careful about, is that when you apply a default deny rule to the namespace, no other namespace can access it, not even the system level components like kube-system. This includes the ingress controller, PostgreSQL operator (if you have deployed a cluster in the namespace) and Prometheus.
For example, CloudNativePG is very specific about needing network policy in this case.
The solution to that is to have rules, which do allow the necessary traffic from these system level components. There's a few ways to handle this, depending on the capability of your users:
- Leave it like it is, and tell your users to add necessary rules for all components they plan to use.
- This method is probably the most secure, as it's very explicit, but it's also very difficult for users, and requires you to have good documentation for them.
- Write those rules into the default network policy that is deployed to all namespaces.
- This is slightly less secure (but still tremendously better than not having rules!), because you'll be opening traffic to namespaces which do not require it.
- Use Kyverno to automatically deploy network policy rules when a specific object is created.
- This is the best compromise between usability and security, and puts the main responsibility on cluster admins. This solution is difficult to implement only for cluster administrators, as the rules can get complicated.
Here is an example of a Kyverno rule, that, when a CloudNativePG cluster gets defined in a namespace, it creates a NetworkPolicy in the namespace to allow the CloudNativePG operator to connect to the defined cluster.
Kyverno rule (click here)
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: generate-networkpolicy-for-cnpg-operator
spec:
generateExisting: true
rules:
- name: check-labels-and-generate
match:
resources:
kinds:
- postgresql.cnpg.io/v1/Cluster
generate:
synchronize: true
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
name: "{{ request.object.metadata.name }}-cnpg-policy"
namespace: "{{ request.object.metadata.namespace }}"
data:
spec:
podSelector:
matchLabels:
cnpg.io/cluster: "{{ request.object.metadata.name }}"
policyTypes:
- Ingress
ingress:
- from:
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: cnpg-system # Namespace where the operator is deployed
podSelector:
matchLabels:
app.kubernetes.io/name: cloudnative-pg # Matches the Operator pod
ports:
- protocol: TCP
port: 5432 # Postgresql
- protocol: TCP
port: 8000 # Status
Cluster Security labs' tasks¶
This week's task is simple:
- turn
generateExistingfor the generate rule intotrue. - Add appropriate Pod Security Admission labels to all namespaces.
This may break bits and pieces of your previous labs functionality, which is visible in scoring by specific tests failing for previous weeks. Your task is to fix these tests.
Checks will verify that all your namespaces (except kube-system, longhorn-system and kyverno) have the default network policy named default-deny, and that all namespaces have the Pod Security Admission rules setup. Normal namespaces should have the same policy as defined in the add-psa-labels rule. The namespaces excluded in the add-psa-labels rule should have privileged instead of baseline policy.
Important
By default, Cilium does not manage the Kubernetes control-plane components, like kube-api. This is due to a so-called chicken-and-egg problem, where these components need to be running before Cilium is. But if Cilium managed them, they could not start before Cilium is up. Cilium on the other hand cannot startup without the components.
You can check which endpoints are managed in Cilium with the following commands:
kubectl -n kube-system exec ds/cilium -- cilium status --verbose
kubectl -n kube-system exec ds/cilium -- cilium identity list
Being unmanaged by Cilium means, you cannot make Kubernetes NetworkPolicy objects that allow or deny traffic to these specific objects, but the default policy still blocks access from them. This basically causes a situation where you cannot allow traffic from them.
This usually isn't a problem, but in labs, the Nagios tests rely on proxying requests through the API server. Solving this requires us to use a Cilium-specific CiliumClusterwideNetworkPolicy manifest, and tell it to allow access to all endpoints from everything in the cluster, including kube-apiserver:
apiVersion: "cilium.io/v2"
kind: CiliumClusterwideNetworkPolicy
metadata:
name: "allow-kubeapi"
spec:
endpointSelector: {}
ingress:
- fromEntities:
- kube-apiserver
- all
Make sure to deploy this into your cluster, otherwise Nagios checks will not work for some resources.