Lab 7 - Container Lifecycle Management
Introduction¶
Welcome to the lab 7. In this session, the following topics are covered:
- Container liveness and readiness probes;
- Affinity and anti-affinity.
At the end of the lab, we will also implement a new use case microservice - application server, which is an HTTP API backend service that will recommend when to turn on electric devices based on tomorrows electricity prices.
Container probes¶
As we already know. Kubernetes manages lifecycle of the Pods in the cluster. But what exactly reports a container's state? By default, Kubernetes considers a Pod as running when an initial process started. An example: when a user starts an application server, it could take some time to boot up, apply migrations and start listening on a port. During this phases, the server can't process external requests, but Kubernetes doesn't know about it. In order to report container status, three types of probes exist:
- liveness - application is healthy and is considered as successfully running. When a probe fails, Kubernetes restarts a Pod;
- readiness - application is healthy and ready to process external requests. When a probe fails, Kubernetes don't forward requests sent to the app through a Service;
- startup - application has started successfully and initial actions performed well. If defined, the probe starts before the previous two. Also unlike them, this one performs only once and then is replaced by a liveness probe.
A probe can be a simple shell command (cat /var/run/app.pid) or a network check (TCP, HTTP, RPC). When an action finishes with successful code 0, container is marked as healthy by Kubernetes.
Liveness Probes¶
Complete
Let's delete the existing pod for echoserver:
kubectl delete pod echoserver
apiVersion: apps/v1
kind: Deployment
metadata:
name: echoserver
spec:
selector:
matchLabels:
app: echoserver
template:
metadata:
name: echoserver
labels:
app: echoserver
spec:
containers:
- name: echoserver
image: registry.hpc.ut.ee/mirror/ealen/echo-server:latest
ports:
- containerPort: 80
env:
- name: PORT
value: "80"
livenessProbe: #(1)
initialDelaySeconds: 10 #(2)
periodSeconds: 5 #(3)
failureThreshold: 5 #(4)
httpGet:
port: 80
path: /
- The probe checks if a process listens on port 80 and responses with 200 HTTP OK code.
- Initial delay before first probe performs.
- A time period between checks in seconds.
- Number of failed checks before the Pod marked as unhealthy and gets restarted.
Validate
You can check the Pod status using this command (-w stands for "wait"):
kubectl get pods -l app=echoserver -w
Let's see how Kubernetes acts when a Pod fails liveness probes more then failureThreshold. For this, change the port in the probe config to 81 and apply the new manifest. You should see a similar result to this one:
kubectl get pods -l app=echoserver -w
# NAME READY STATUS RESTARTS AGE
# echoserver-7f655fd6f5-c4gjq 1/1 Running 0 8s
# echoserver-7f655fd6f5-c4gjq 1/1 Running 1 (2s ago) 37s
# echoserver-7f655fd6f5-c4gjq 1/1 Running 2 (2s ago) 72s
# echoserver-7f655fd6f5-c4gjq 1/1 Running 3 (2s ago) 107s
# echoserver-7f655fd6f5-c4gjq 1/1 Running 4 (2s ago) 2m22s
# echoserver-7f655fd6f5-c4gjq 0/1 CrashLoopBackOff 4 (1s ago) 2m56s
CrashLoopBackOff status indicates the Pod doesn't pass the checks and Kubernetes restarts it infinitely. Please, restore the correct port value for the probe.
Readiness Probes¶
Complete
Let's setup the readiness probe for the same Deployment:
apiVersion: apps/v1
kind: Deployment
...
livenessProbe:
...
readinessProbe:
initialDelaySeconds: 15
periodSeconds: 5
failureThreshold: 5
httpGet:
port: 80
path: /
It has the same content but a different impact when checks fail.
Validate
The echoserver Pod should be up and running. You can view the Deployment status and ensure there is one available Pod:
kubectl get deployment echoserver
# NAME READY UP-TO-DATE AVAILABLE AGE
# echoserver 1/1 1 1 37m
Let's change the port for the probe (e.g. 81), apply the new manifest and list the echoserver Pods.
kubectl get pod -l app=echoserver
# NAME READY STATUS RESTARTS AGE
# echoserver-6d87869565-7fp6z 0/1 Running 0 15s
# echoserver-7c7746c59b-mwz87 1/1 Running 0 7m53s
As you can see, there are two Pods: the old one is running and has all containers ready, while the new one is hanging. Kubernetes doesn't remove existing Pods from a Deployment, when new ones are not ready. The deployment is available, because at least one Pod is ready:
kubectl get deployment echoserver
# NAME READY UP-TO-DATE AVAILABLE AGE
# echoserver 1/1 1 1 6m17s
Let's also check how Services behave when a Pod is not ready. For this, remove the deployment and apply the manifest with readiness probe checking an incorrect port (e.g. 81).
kubectl get pods -l app=echoserver
# NAME READY STATUS RESTARTS AGE
# echoserver-84b767ff89-jfdl8 0/1 Running 0 84s
There is only one Pod now. If you try to curl this Pod through the Service we created in networking lab, you should get "connection refused" status:
kubectl get service echoserver
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# echoserver ClusterIP 10.106.242.153 <none> 80/TCP 33d
curl 10.106.242.153
# curl: (7) Failed to connect to 10.106.242.153 port 80: Connection refused
This indicates Kubernetes doesn't forward any traffic to the Pod through the Service, because the container isn't ready. You can still access the Pod using it's IP, while other application relying on the Service can't.
ECHOSERVER_IP=$(kubectl get pod -l app=echoserver -o jsonpath={.items[0].status.podIP})
curl $ECHOSERVER_IP
# {"host":{"hostname":"10.0.1.184"
# ...
In real-life production systems, avoiding external communication, when an application isn't ready, can be crucial.
Please, restore the correct port (80) in the readiness probe of the deployment.
Complete
For this section, you need to define liveness and readiness probes for the history-sever deployment similar to the ones we created before.
PS! For liveness or readiness probes to work properly, your history-server API should have an API endpoint that responds without an Error (e.g. HTTP 200 OK code), even when no data has been inserted yet to the database.
Pods scheduling¶
Kubernetes allows setting requirements for a scheduler, so that a Pod runs on a subset of nodes with/without particular labels.
nodeSelector field¶
The simplest way to restrict set of nodes for a Pod is usage of nodeSelector field, which accepts a map of node labels.
Complete
First of all, let's view node labels in the Kubernetes cluster:
kubectl get nodes --show-labels
# NAME STATUS ROLES AGE VERSION LABELS
# sergei-k8s-control-plane.cloud.ut.ee Ready control-plane 23d v1.30.5 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=sergei-k8s-control-plane.cloud.ut.ee,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node.kubernetes.io/exclude-from-external-load-balancers=
# sergei-k8s-worker-01.cloud.ut.ee Ready <none> 91s v1.30.5 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=sergei-k8s-worker-01.cloud.ut.ee,kubernetes.io/os=linux
# sergei-k8s-worker.cloud.ut.ee Ready <none> 23d v1.30.5 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=sergei-k8s-worker.cloud.ut.ee,kubernetes.io/os=linux
The output contain standard set of labels for each node. Let's add a label to one of the worker nodes. In the example, we use sergei-k8s-worker.cloud.ut.ee node:
kubectl label nodes sergei-k8s-worker.cloud.ut.ee custom-role=worker
# node/sergei-k8s-worker.cloud.ut.ee labeled
NB: use the hostname of your VM.
Verify
Check if the node get the label using the command a kubectl get nodes --show-labels
Complete
In this task, we need to make echoserver run on this worker node only. You can view the current node, where the Pod run, via the command:
kubectl get pods -l app=echoserver -o wide
# NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
# echoserver-54f9bcc9cf-br2gh 1/1 Running 0 41s 10.0.2.14 sergei-k8s-worker-01.cloud.ut.ee <none> <none>
In this example, the Pod is already running on the worker node, but this can change when after the redeployment. Set nodeSelector for the Pod template in the echoserver deployment do ensure this requirement:
apiVersion: apps/v1
kind: Deployment
metadata:
name: echoserver
spec:
selector:
matchLabels:
app: echoserver
template:
metadata:
name: echoserver
labels:
app: echoserver
spec:
nodeSelector: #(1)
custom-role: worker #(2)
...
- Selects a node within the cluster with the provided labels.
- The label with the required value.
Apply the new manifest to the node and check the result with the command we used before. The Pod should run on the worker node with the correct label.
Node affinity and anti-affinity¶
In case if you need to define advanced rules for node selection, affinity/anti-affinity can help. The main differences of this approach from nodeSelector are:
- Selectors can be soft requirements, so Pods will run on a node even if it doesn't satisfy the rules;
- Support for selection for other Pods, so that two Pod sets can be scheduled on the same node or vice versa.
There are two rule types for node affinity: requiredDuringSchedulingIgnoredDuringExecution and preferredDuringSchedulingIgnoredDuringExecution. The first one is a requirement working like a nodeSelector, the second one - same, but a preference. IgnoredDuringExecution part means the Pods with the constraints will continue running on a node even if node labels are changed.
Complete
In this section, you need to replace nodeSelector field with affinity for the existing echoserver deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: echoserver
spec:
selector:
matchLabels:
app: echoserver
template:
metadata:
name: echoserver
labels:
app: echoserver
spec:
affinity: #(1)
nodeAffinity: #(2)
requiredDuringSchedulingIgnoredDuringExecution: #(3)
nodeSelectorTerms: #(4)
- matchExpressions:
- key: custom-role
operator: In
values:
- worker
...
- Affinity section.
- Specifies the node affinity.
- This is a requirement, not a preference.
- A set of expressions with subject-operator-object(s) style. In this case the
custom-rolelabel of a node should haveworkervalue
As you can see, the syntax is much more expressive and provides better flexibility over node selection.
Verify
Apply the manifest and check that the new Pod is running on the same worker node. Example:
kubectl get pods -l app=echoserver -o wide
# NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
# echoserver-6bc5578654-d25xs 1/1 Running 0 33s 10.0.1.217 sergei-k8s-worker.cloud.ut.ee <none> <none>
Complete
Let's setup a Pod anti-affinity for a second echoserver deployment. For this, create a similar manifest with a different affinity config:
apiVersion: apps/v1
kind: Deployment
metadata:
name: echoserver-2
spec:
selector:
matchLabels:
app: echoserver-2
template:
metadata:
name: echoserver-2
labels:
app: echoserver-2
spec:
affinity:
podAntiAffinity: #(1)
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector: #(2)
matchExpressions:
- key: app
operator: In
values:
- echoserver
topologyKey: "kubernetes.io/hostname" #(3)
...
- Inter-pod anti-affinity section for the deployment.
- In this case, Kubernetes can't schedule a workload on a node, where Pods with the
app=echoserverlabel are running. - Specifies the context where rule applies:
hostnamemeans selection for nodes. In case ofzonevalue, the Pod would be scheduled in a different set of nodes.
Verify
Apply the manifest and check if the new Pod is running on a different node then the previous one. Example:
kubectl get pods -o wide | grep "echoserver"
# echoserver-2-6488c87476-7vk7f 1/1 Running 0 22s 10.0.2.149 sergei-k8s-worker-01.cloud.ut.ee <none> <none>
# echoserver-6bc5578654-d25xs 1/1 Running 0 31m 10.0.1.217 sergei-k8s-worker.cloud.ut.ee <none> <none>
Complete
Now you need to create an affinity rule for history-server deployment: it should run on a node with custom-role=worker label.
Use-case¶
In this lab, you will implement one more use case microservice: an application server. It should be an HTTP API server, which suggests an optimal time to turn on some electrical device based on electricity prices of tomorrow (or some specific day). Request contains a date and the length of time (in hours) for turning on a device.
Info
The server should have the following endpoints:
GET /api/optimal-prices/?length=<num_hours>&day=<date>- find the cheapest period of lengthnum_hourshours for the specified date (format should be day=2024-09-29).GET /api/health- Respond with HTTP code 200 and a message that application server is working properly (The message must contain the word 'properly').
For example, when a user requests for the best time to turn on a washing machine on 2024-10-14 for 3 hours, the server downloads the prices from the history data server and responds with the period that has the minimal combined price and the calculated price value itself.
Example of an HTTP request:
GET http://application-server:80/api/optimal-prices/?length=3&day=2024-10-14
If the list of prices (in the order of hours) for 2024-10-14 are: [71.69, 82.29, 97.48, 110.27, 208.64, 332.31, 542.5, 693.63, 685.21, 585.21, 400.02, 408.61, 392.57, 436.85, 378.12, 361.21, 373.99, 528.3, 678.82, 679.83, 539.75, 371.85, 308.65, 301.12].
Then the cheapest price of a consecutive 3 hours is 251.46, between hour 0 and hour 2 when the prices were [71.69, 82.29, 97.48].
Example of a server response:
{
"start-time": "2024-10-14T00:00:00+03:00",
"end-time": "2024-10-14T03:00:00+03:00",
"total-price": 251.46
}
NB! Recently, Elering has changed the reporting from 1 hour increments into 15 minute increments.
For the computation of the cheapest period, you could use an existing implementation for computing sums over a window in an array (for example sliding_window_view() method in Python numpy library), or implement a simple loop over the price list that computes every possible sum and keeps track of the smallest. To clarify, the time period is always of fixed length (For example: 4 hours) and the period can not be divided into multiple smaller periods.
Here is a visualisation of the use case after we add the Application Server microservice:
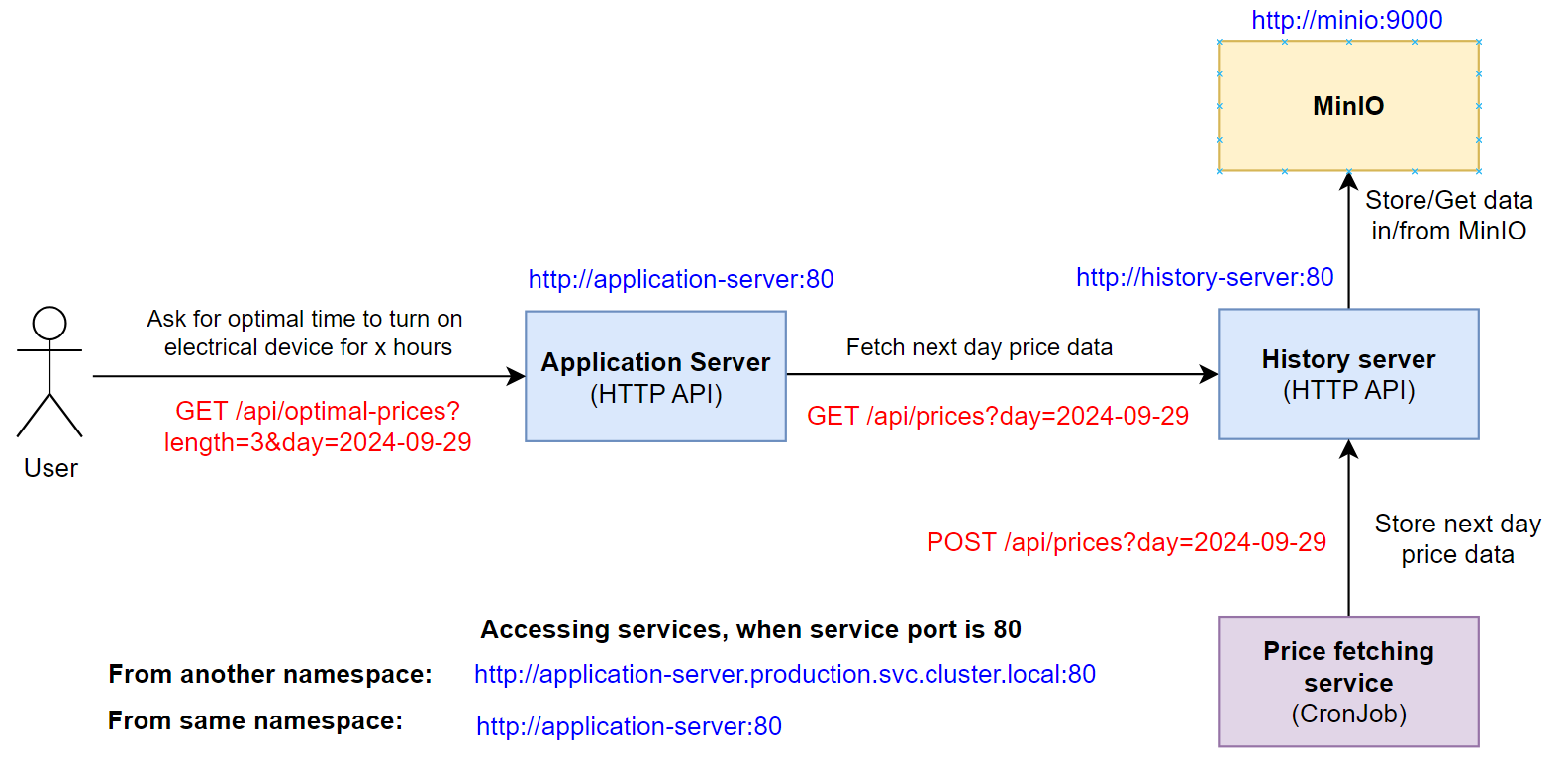
An example of a similar application (in Estonian language) is here the Elektrikell.
Complete
- Implement the microservice in a freely chosen programming language.
- Create a Dockerfile for the app server and publish it to Dockerhub.
- Create a Deployment for the application server microservice.
- Create a ClusterIP type Service for the application server microservice.
If you are unsure what languages and frameworks to use, we suggest using Python FastAPI or Flask libraries. Here is an basic example of a Flask API implementation, where the logic is not implemented yet: Application server Flask code skeleton. Also, we have provided an OpenAPI specification, if you want to generate the server code: Application server OpenAPI specification
The name of the deployment and service should be application-server. The app label value should be the same as other microservices and the microservice label value should be application-server. Also add a label for the application software version app-version:1.0.
Make sure to define the containerPort (The port that application is listening inside the container) for the application-server inside the Deployment manifest. It is required for one of the scoring checks.
Also, the message returned by the /api/health endpoint must contain the word properly, as this is checked by the scoring bot. For example: "Server is working properly".
Validation
Send a HTTP POST request at the address of the application-server service IP for either today or tomorrow (if prices have been downloaded already for tomorrow) and check that the application reponds with correct information.